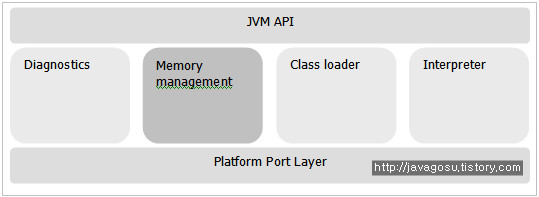
JVM 구조
IBM JVM를 구성하는, 각각의 Component structure는 아래와 같이 나뉜다.
각 영역의 주요 기능은 아래와 같이 요약된다.
구분 | 기능 |
JVM API | JVM와 External program 사이의 상호작용에 관여 |
Diagnostics | JVM의 기능에 편리성과 유용성(RAS)을 제공 |
Memory management | Java application에 의한 System memory 효율적인 사용에 관여함 |
Class loader | Java code의 동적 로딩의 편리성 제공 |
Interpreter | Stack-base bytecode 해석에 관여함 |
Platform port layer | 다양한 운영시스템에서 JVM이 native function을 사용할 수 있도록하는 기능제공 |
[표 1] IBM JVM 구성 요소 설명
여기서 우리는 ‘Memory management’ 를 중점적으로 다뤄본다.
JIT 컴파일러
흔히, IBM JVM을 JIT계열의 JVM이라고 표현한다.
JIT는 흔히 Just-In-Time의 약자로 알려져 있으며, 이는 JVM의 한 part라기 보다는, SDK의 기본 구성요소로 생각하는 것이 맞다.
Java가 Interpreter 언어이고, 이는 소스가 bytecode로 컴파일 되고, 실행되기 위해서는 다시금 system code로 해석되어 수행되어야 하는, performance적인 저하요소를 극복하기 위해 자주 수행되는 Java method를 대상으로 미리 system code로해석해서, Method가 call되면 컴파일 과정 없이 바로 서비스를 하는 방식으로 작동한다.
이런 JIT 컴파일러가 때때로 Runtime시 문제점이 발생하는 경우는, 아래의 방법으로 JIT 옵션을 꺼둘 수도 있다.
구분 | 설명 |
Unix 환경변수 제어방법 | Korn 쉘 : export JAVA_COMPILER=NONE Bourne 쉘 : JAVA_COMPILER=NONE export JAVA_COMPILER C 쉘 : setenv JAVA_COMPILER NONE |
JVM Option 1 | -Djava.compiler=NONE |
JVM Option 2 | -Xint |
[표 2] JIT 컴파일러 비활성화
또, 아래와 같이 JIT 옵션을 켤 수도 있다.
구분 | 설명 |
Unix 환경변수 제어방법 | Korn 쉘 : exprt JAVA_COMPILER=jitc Bourne 쉘 : JAVA_COMPILER=jitc export JAVA_COMPILER C 쉘 : setenv JAVA_COMPILER jitc |
JVM Option 1 | -Djava.compiler=jitc |
JVM Option 2 | -Xjit |
[표 3] JIT 컴파일러 활성화
Garbage Collector
Sun의 HotSpot 계열의 JVM은 ‘New/Old/Permanent’등의 ‘세대(Generation)’로 불리는 영역으로 분리된 Heap구조를 가진다.
이에 반해, IBM JVM은 영역이 따로 분리되지 않은 하나의 ‘Single Space’로 Heap이 구성되어 있다.
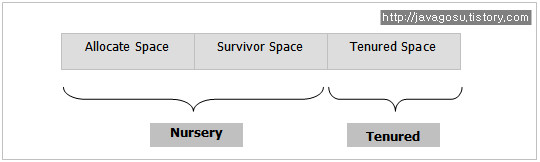
참고로, IBM JDK 1.5부터는 아래와 같이 ‘세대(Generation)’기반의 Heap 구조를 지원한다.
(GC 알고리즘이 Concurrent Generational Collector 인 경우의 Heap 구조임)
각 영역이 어떤 식으로 Garbage Collector에 의해 사용되는지 설명하기 위해서,
‘Generational Concurrent Garbage Collection’의 알고리즘에 대해 잠깐 언급하도록 한다.
JVM이 Logic을 처리하는 동안, 새로운 Object들은 당연히 ‘Nursery’영역에 생기게 된다. 만일, 새로운 Object가 할당되는데 필요한 ‘연속된 메모리 영역’이 부족하게 되면, 객체는 ‘Tenured’영역으로 옮겨지게 된다. 또한, Garbage collection 발생시 옮겨지기도 한다.
Nursery 영역은 ‘Allocate Space’와 ‘Survivor Space’로 나뉘게 된다.
Object는 최초 Allocate Space에 생기게 된다. 만일, Space가 부족하게 되는 경우,
Allocation Failure가 발생되면 Garbage Collector가 작동되고, Scavenge가 시작된다.
Scavenge가 진행되는 동안, reference가 살아있는 Object들은 ‘Survivor Space’로 이동되고, 이때 reference가 없는Object들은 건들지 않는다.
Reference가 살아있는 Object들의 이동작업이 다 끝나게 되면, ‘Allocate Space’와 ‘Survivor Space’는 그 역할을 순간적을 바꾸게 된다.
이때, 기존의 reference가 없는 Object들은 순간적으로 비워지게 된다. 그리고, 다음 Scavenge가 발생할 때 까지는‘Survivor Space’가 Object를 위한 Allocate 공간 업무를 수행하게 된다.
GC command-line options
-verbose:gc
garbage collection 의 정보를 standard out 으로 출력한다.
-Xverbosegclog:<file, X, Y>
garbage collection 의 정보를 파일로 출력한다. 만약 integer X와 Y의 값을 명시하면 output이 Y GC Cycle의 output을 포함하는 X 파일로 재지정된다.
예) -Xverbosegclog:/user/logs/gclog/gclog.log //로그 경로 설정
-Xgcpolicy: <optthruput | optavgpause | gencon | subpool>
이 option은 garbage collector 행동을 제어한다.
-. optthruput
concurrent mark를 비활성화 한다. 만약 application response time에 문제가 없다면 이 option을 사용하여 최적의throughput을 낼 수 있다. Optthruput은 default 값이다.
-. optavgpause
concurrent mark를 활성화 한다. 만약 일반적인 garbage collections 에 의해 application response time에 문제가 있다면이 option을 사용함으로 문제를 줄일 수 있다.
-. gencon
Concurrent와 generational GC를 겸용하여 사용함으로 garbage collection 지체 시간을 최소화 할 수 있다.
-. subpool
concurrent mark를 비활성화 한다. 이것은 heap에 객체들을 배치할 때 더 나은 성능을 내기 위해 향상된 object allocation알고리즘을 사용한다. 이 option은 16 이상의 processor의 SMP system에서 실행되며, subpool option은 AIX, Linux PPC 와 zSeries, z/OS, i5/OS 에서 가능하다.
-Xmx<value>
최대 heap size를 지정한다. (Xmx >= Xms)
예) -Xmx256m // 최대 heap size를 256mb 로 지정한다.
-Xms<value>
최소 heap size를 지정한다. Xmo 또한 사용할 수 있다. 최소 size는 8KB이다.
scavenger 가 활성화 되어 있을 경우, -Xms >= -Xmn + -Xmo
scavenger 가 비활성화 되어 있을 경우, -Xms >= -Xmo
예) -Xms256m // 최소 heap size를 256mb 로 지정한다.
-Xcompactgc
모든 garbage collections(system 또는 global) 에 대하여 압축을 가능하게 한다.
-Xnocompactexplicitgc
System.gc() 호출에 의한 압축을 불가능하게 한다. 압축은 만약 –Xcompactgc 명시하거나 또는 compaction triggers를 만나면 global garbage collections 에서 발생한다.
-Xcompactexplicitgc
System.gc()가 호출 될 때마다 모든 GC 시스템에서 압축을 사용 가능하게 한다.
-Xnocompactgc
모든 garbage collections(system 또는 global) 에 대하여 압축을 사용 불가능하게 한다.
-Xnoclassgc
Class garbage collection 을 비활성화 한다. JVM에 의해서 더 이상 사용되지 않는 Java class 들과 연관된 storage의garbage collection을 끈다. 즉 dynamic 클래스 로드 해제를 사용 불가능하게 한다.
-Xclassgc
dynamic 클래스 로드 해제를 사용 가능하게 한다.
-Xalwaysclassgc
global collection 동안 항상 dynamic class load 해제를 수행한다. Default 는 -Xclassgc 에 의해 정의된다.
-Xmaxf<percentage>
garbage collection 후 free 되어야 하는 heap의 최대 percentage를 지정한다. 만약 free 영역이 이 값을 초과하면 JVM은heap을 줄이기 위해 시도한다. Default는 0.6(60%) 이다.
-Xminf<percentage>
garbage collection이후 free되어야 하는 heap의 최소 percentage를 지정한다. 만약 free영역 이 값에 못 미치는 경우 JVM은 heap을 확장하기 위해 시도한다. Default는 30%이다.
-Xgcthreads<number>
Garbage Collector 의 thread 수를 지정한다. Default는 물리적인 CPU의 수로 지정된다. 다른 수로 지정하기 위해 (예를 들어 4) -Xgcthreads4 로 표기한다.
Nonstandard command-line options
-Xss<size>
모든 Java thread의 최대 stack size를 지정한다. Default는 32bit JVM에서 256KB, 64bit JVM에서 512KB 이다.
-Xmso<size>
OS thread의 stack size를 지정한다.
JIT command-line options
-Xint
JVM을 JIT로 사용불가하고, Interpreter 로만 사용한다.
-Xquickstart
최적화를 지연하여 시작 시간을 향상시킨다.
GC 알고리즘의 이해
IBM JDK에서는 아래와 같이 주요 4가지 Garbage Collection 옵션을 제공한다.
이들은 아래와 같은 방법으로 설정이 가능하다.
여기에 설정할 수 있는 옵션은 다음과 같다.
optthruput GC 알고리즘 설명
구분 | 설명 |
옵션 예 | -Xgcpolicy:optthruput |
설명 | 이 옵션은 default GC 알고리즘 이다. 특징으로는, 작동 시 ‘일시적으로 정지’하는 현상이 발생한다는 점이다. Object할당을 시도할 때, Allocation Failure가 발생하게 되면, Garbage Collector는 reference가 끊긴 Object를 수집하여 삭제하게 된다. 이때, 필연적으로 JVM이 Lock이 걸리면서 멈추는 현상이 발생하게 된다. Application이 복잡해지고, 그에 따라 Heap이 커지게 되면, 역시 GC발생시 멈추게 되는 시간도 증가하게 된다. |
장점 | Throughput이 향상될 수 있다.
(General GC, Disable concurrent mark) |
단점 | 작동 시 ‘일시적으로 정지’하는 현상이 발생한다. |
optavgpause GC 알고리즘 설명
구분 | 설명 |
옵션 예 | -Xgcpolicy:optavgpause |
설명 | 위에서 설명한 ‘optthruput’ GC 알고리즘의 단점인 ‘JVM 정지시간’을 보완하기위한 GC 알고리즘 중 하나이다. 이는, Application이 수행 중 일 때, Garbage Collection을 위한 Thread를추가적으로 생성하고 기동시켜서, reference가 끊긴 Object들에 대한 scavenge작업을 수행시켜서, 실제 Garbage Collector가 수행될 때, 전체 Heap영역에 대한 Object선별작업을 수행할 필요 없이 reference가 끊긴 Object들만을 수거해갈 수 있도록 돕는다. |
장점 | 전반적인 응답속도(Response Time)가 향상하는 효과를 가져올 수 있다. (Enables concurrent mark) |
단점 | Concurrent한 Thread 기동에 의한, 실제 Application 수행에 있어서의 Throughput이 감소한다. |
gencon GC 알고리즘 설명
구분 | 설명 |
옵션 예 | -Xgcpolicy:gencon |
설명 | 해당 옵션이 설정되면, JVM은 할당된 Heap을 ‘세대(Generation)’기준으로 분류한다. 이는 위에서 살펴보았듯이, ‘Nursery Space’와 ‘Tenured Space’를 말한다. JVM이 Logic을 처리하는 동안, 새로운 Object들은 당연히 ‘Nursery’영역에 생기게된다. 만일, 새로운 Object가 할당되는데 필요한 연속된 메모리 영역이 부족하게 되면 객체는 Tenured 영역으로 옮겨지게 된다. 또한, Garbage collection 발생시 옮겨지기도 한다. Nursery 영역은 ‘Allocate Space’와 ‘Survivor Space로 나뉘게 된다. Object는 최초 Allocate Space에 생기게 된다. 만일, Space가 부족하게 되는경우, Allocation Failure가 발생되면, Garbage Collector가 작동되고, Scavenge가 시작된다. Scavenge가 진행되는 동안 reference가 살아있는 Object들은 SurvivorSpace로 이동되고, 이때 reference가 없는 Object들은 건들지 않는다. Reference가 살아있는 Object들의 이동작업이 다 끝나게 되면, Allocate Space와 Survivor Space 는 그 역할을 순간적을 바꾸게 된다. 이때, 기존의 reference가 없는 Object들은 순간적으로 비워지게 된다. 그리고 다음 Scavenge가 발생할 때 까지는 Survivor Space가 Object를 위한 Allocate공간 업무를 수행하게 된다. |
장점 | 전반적인 응답속도(Response Time)와, Throughput이 동시에 평균적으로 향상하는효과를 가져올 수 있다.
(Enable concurrent mark + General GC) |
단점 | CPU overhead가 상대적으로 발생할 수 있다. |
subpool GC 알고리즘 설명
구분 | 설명 |
옵션 예 | -Xgcpolicy:subpool |
설명 | Heap 공간을 다수의 sub pool로 할당하여 Object를 관리하는 기법이다. 여기에 LOA(Large Object Area)와 SOA(Small Object Area)의 개념이 들어간다. |
장점 | 상대적으로 높은 성능을 발휘한다. |
단점 | 16 CPU 이상의 고 사양 서버 환경에서 사용해야 한다. 또한, AIX, z/OS, Linux PPC 등 특정 플랫폼에서만 사용할 수 있다. |
GC Dump의 이해
앞에서, GC 알고리즘에 대해 개략적으로 살펴보았다.
여기서는, 로그가 실제 어떤 식으로 생성되는지 간략한 예를 살펴보도록 한다.
아래는, 실제로 JEUS에 각각의 GC 알고리즘을 적용시켜 생성한 Dump이다.
–Xgcpolicy:optthruput GC dump
<af type="tenured" id="4" timestamp="목 2월 28 10:16:42 2008" intervalms="432.499">
<minimum requested_bytes="33562648" />
<time exclusiveaccessms="0.140" />
<tenured freebytes="158830512" totalbytes="536870912" percent="29" >
<soa freebytes="136268104" totalbytes="493921280" percent="27" />
<loa freebytes="22562408" totalbytes="42949632" percent="52" />
</tenured>
<gc type="global" id="5" totalid="5" intervalms="434.640">
<compaction movecount="450409" movebytes="69221728" reason="heap fragmented" />
<refs_cleared soft="0" threshold="32" weak="0" phantom="0" />
<finalization objectsqueued="0" />
<timesms mark="72.584" sweep="5.045" compact="130.030" total="207.766" />
<tenured freebytes="340455528" totalbytes="536870912" percent="63" >
<soa freebytes="292138088" totalbytes="488553472" percent="59" />
<loa freebytes="48317440" totalbytes="48317440" percent="100" />
</tenured>
</gc>
<tenured freebytes="306892880" totalbytes="536870912" percent="57" >
<soa freebytes="258575440" totalbytes="488553472" percent="52" />
<loa freebytes="48317440" totalbytes="48317440" percent="100" />
</tenured>
<time totalms="208.154" />
</af>
로그 패턴을 보면, Allocation Failure가 발생하였고, GC를 거쳐 Tenured영역의 Free Space가 57%로 증가했음을 알 수있다.
–Xgcpolicy:optavgpause GC dump
<af type="tenured" id="40" timestamp="목 2월 28 10:17:02 2008" intervalms="223.402">
<minimum requested_bytes="37748760" />
<time exclusiveaccessms="36.573" />
<tenured freebytes="28931592" totalbytes="1073741824" percent="2" >
<soa freebytes="28931592" totalbytes="1073741824" percent="2" />
<loa freebytes="0" totalbytes="0" percent="0" />
</tenured>
<gc type="global" id="42" totalid="42" intervalms="223.577">
<refs_cleared soft="0" threshold="32" weak="0" phantom="0" />
<finalization objectsqueued="0" />
<timesms mark="28.562" sweep="3.428" compact="0.000" total="32.092" />
<tenured freebytes="211487536" totalbytes="1073741824" percent="19" >
<soa freebytes="211487536" totalbytes="1073741824" percent="19" />
<loa freebytes="0" totalbytes="0" percent="0" />
</tenured>
</gc>
<tenured freebytes="173738776" totalbytes="1073741824" percent="16" >
<soa freebytes="173738776" totalbytes="1073741824" percent="16" />
<loa freebytes="0" totalbytes="0" percent="0" />
</tenured>
<time totalms="68.845" />
</af>
–Xgcpolicy:gencon GC dump
<af type="tenured" id="154" timestamp="금 2월 29 09:57:50 2008" intervalms="452.265">
<minimum requested_bytes="37748760" />
<time exclusiveaccessms="2.137" />
<nursery freebytes="33161216" totalbytes="33554432" percent="98" />
<tenured freebytes="242872304" totalbytes="1006632960" percent="24" >
<soa freebytes="211147296" totalbytes="956301312" percent="22" />
<loa freebytes="31725008" totalbytes="50331648" percent="63" />
</tenured>
<gc type="global" id="226" totalid="1071" intervalms="452.406">
<refs_cleared soft="0" threshold="32" weak="0" phantom="0" />
<finalization objectsqueued="8" />
<timesms mark="26.053" sweep="3.163" compact="0.000" total="29.278" />
<nursery freebytes="33494840" totalbytes="33554432" percent="99" />
<tenured freebytes="470984032" totalbytes="1006632960" percent="46" >
<soa freebytes="439259024" totalbytes="946235392" percent="46" />
<loa freebytes="31725008" totalbytes="60397568" percent="52" />
</tenured>
</gc>
<nursery freebytes="33494840" totalbytes="33554432" percent="99" />
<tenured freebytes="433235272" totalbytes="1006632960" percent="43" >
<soa freebytes="401510264" totalbytes="946235392" percent="42" />
<loa freebytes="31725008" totalbytes="60397568" percent="52" />
</tenured>
<time totalms="31.585" />
</af>
<af type="nursery" id="881" timestamp="금 2월 29 09:57:50 2008" intervalms="285.580">
<minimum requested_bytes="37748760" />
<time exclusiveaccessms="0.110" />
<nursery freebytes="31100848" totalbytes="33554432" percent="92" />
<tenured freebytes="433235272" totalbytes="1006632960" percent="43" >
<soa freebytes="401510264" totalbytes="946235392" percent="42" />
<loa freebytes="31725008" totalbytes="60397568" percent="52" />
</tenured>
<gc type="scavenger" id="846" totalid="1072" intervalms="285.732">
<flipped objectcount="3460" bytes="171648" />
<tenured objectcount="0" bytes="0" />
<refs_cleared soft="0" weak="0" phantom="0" />
<finalization objectsqueued="0" />
<scavenger tiltratio="50" />
<nursery freebytes="33013736" totalbytes="33554432" percent="98" tenureage="3" />
<tenured freebytes="433235272" totalbytes="1006632960" percent="43" >
<soa freebytes="401510264" totalbytes="946235392" percent="42" />
<loa freebytes="31725008" totalbytes="60397568" percent="52" />
</tenured>
<time totalms="3.648" />
</gc>
<nursery freebytes="33013736" totalbytes="33554432" percent="98" />
<tenured freebytes="433235272" totalbytes="1006632960" percent="43" >
<soa freebytes="401510264" totalbytes="946235392" percent="42" />
<loa freebytes="31725008" totalbytes="60397568" percent="52" />
</tenured>
<time totalms="3.923" />
</af>
–Xgcpolicy:subpool GC dump
<sys id="1" timestamp="금 2월 29 10:03:16 2008" intervalms="0.000">
<time exclusiveaccessms="0.048" />
<tenured freebytes="373520640" totalbytes="536870912" percent="69" />
<gc type="global" id="1" totalid="1" intervalms="0.000">
<classloadersunloaded count="0" timetakenms="0.973" />
<refs_cleared soft="73" threshold="32" weak="127" phantom="4" />
<finalization objectsqueued="21" />
<timesms mark="56.218" sweep="5.343" compact="0.000" total="62.748" />
<tenured freebytes="491131504" totalbytes="536870912" percent="91" />
</gc>
<tenured freebytes="491131504" totalbytes="536870912" percent="91" />
<time totalms="63.282" />
</sys>
Subpool은 CPU가 16장 이상인 환경에서 최적화 되어있다고 앞서 말했다.
종종 System Capacity가 부족한 환경에서는 아래와 같은 로그가 목격되기도 한다.
Module=/usr/java5_64/jre/bin/libj9gc23.so
Module_base_address=0900000001046000
Target=2_30_20071004_14218_BHdSMr (AIX 5.3)
CPU=ppc64 (4 logical CPUs) (0x1f0000000 RAM)
위의 로그와 비슷하게, System.gc()가 명시적으로 호출된 경우는 아래와 같은 GC Dump가 발생한다.
<sys id="1" timestamp="금 2월 29 10:03:16 2008" intervalms="0.000">
<time exclusiveaccessms="0.048" />
<tenured freebytes="373520640" totalbytes="536870912" percent="69" />
<gc type="global" id="1" totalid="1" intervalms="0.000">
<classloadersunloaded count="0" timetakenms="0.973" />
<refs_cleared soft="73" threshold="32" weak="127" phantom="4" />
<finalization objectsqueued="21" />
<timesms mark="56.218" sweep="5.343" compact="0.000" total="62.748" />
<tenured freebytes="491131504" totalbytes="536870912" percent="91" />
</gc>
<tenured freebytes="491131504" totalbytes="536870912" percent="91" />
<time totalms="63.282" />
</sys>
Java Thread Dump 분석
Java Thread Dump란, 특정 Java Process에 대한 청사진이라 해석될 수 있다.
IBM 플랫폼에서 Java Thread Dump는 text형태로 생성된다.
이를, 직접 열어서 내용을 Trace하는 것도 가능하지만, 여기서는 Visual Tool을 이용한 분석법을 소개한다.
JCA를 이용한 Java Thread Dump 분석
1. 다운로드 : http://www.alphaworks.ibm.com/tech/jca (파일명:jca*.zip)
2. 실행화면
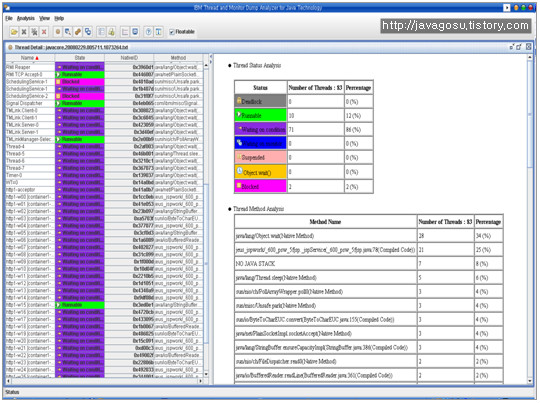
3. 설명
실제 javacore덤프를 분석한 화면이다.
덤프 생성 당시, 가용한 메모리가 없었다는 경고와 함께, Worker Thread들 중 하나가
Running 상태였다는 정보를 쉽게 알 수 있다.
이와 같이, Worker Thread의 상태정보 및 Heap Memory Usage정보, Thread Monitor 상태정보(dead lock)등의 정보에쉽게 접근이 가능하다.
Java Heap Dump 분석
Java Heap Dump란, 특정 Java Process에 allocation 되었던 Heap Memory에 대한 청사진이라 할 수 있다.
IBM 플랫폼에서는 text형태, 혹은 phd(Portable Heap Dump)포맷으로 생성된다.
Heap Dump 분석에는 주로 아래와 같은 방법이 사용된다.
여기서는 GUI기반의 HeapAnalyzer를 소개한다.
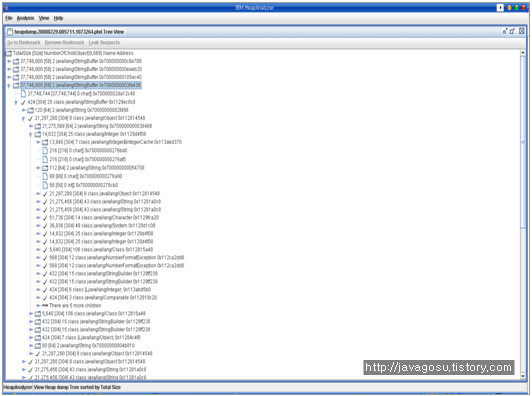
HeapAnalyzer를 이용한 Java Heap Dump 분석
1. 실행화면
2. 설명
실제 Heap Dump를 분석한 화면이다.
Heap Dump 생성 당시의 Memory allocation에 대한 Stack정보를 계층구조로 보여주고 있어서, Memory 누수 라던지OOM(Out Of Memory)상황이 발생하였을 경우, 그 원인파악에 매우 도움이 되는 화면을 제공한다.
(*주의: Heap Dump Size가 매우 큰 경우는, 서버의 X-Window환경에서 작업하도록 한다. 통상적인 Heap Dump 분석에는 많은 Memory가 필요하기 때문이다.)
GC Dump 분석
GC Dump 분석이란, -verbose:gc –Xverbosegelog:logname.log 의 결과로 생성된 GC log파일을 분석하는 것을 말한다.
이 역시, script를 이용하는 방법과 command-line을 이용한 명령어 사용방법 등이 있는데, 여기서는 역시 GUI 기반의 툴인‘GCCollector’를 이용하는 방법을 소개한다.
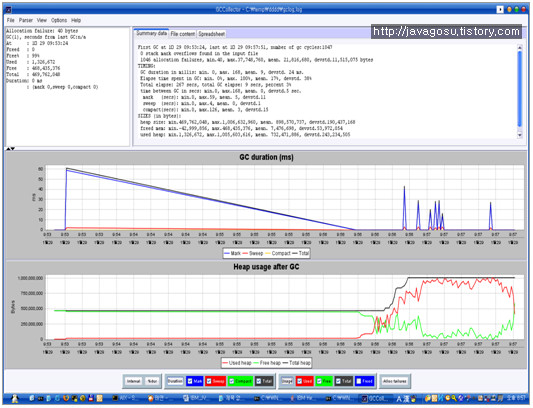
GCCollector를 이용한 GC Dump 분석
1. 다운로드: GCCollector를 실행하기 위해서는 JFreeChart 도 다운받아야 한다.
2. GCCollector 실행파일에 오류가 발생할 경우 아래와 같이 작성한다.
javaw -Xmx300m –classpath lib/GCCollector.jar;lib/jfreechart-1.0.0-rc1.jar;lib/jcommon-1.0.0-rc1.jar it.imperato.jvmperf.GCCollector
3. 실행화면
4. 설명
실제 GC Dump를 분석한 화면이다. (-Xgcpolicy:optthruput or –Xgcpolicy:optavgpause)
GCCollector를 통해 판단할 수 있는 항목은 아래와 같다.
l GC Interval
l GC Duration (Mark, Sweep, Compact, Total)
l Allocation Failure: 실제 Garbage Collector가 작동된 count와 같다고 생각하면 된다.
표준 설정 옵션
표준 옵션 |
-Xms512m -Xmx1024m -verbose:gc -Xverbosegclog:/user/logs/gclog/gclog.log |
전체적인 GC Time이 너무 길고, Response Time이 너무 나오지 않습니다.
상황
GC 수행시간 그래프를 보면, 수행시간이 오래 걸리는 GC들의 peak가 자주 목격됩니다.
Response Time 역시 너무 안 나옵니다.
조치
대부분, GC에 있어서 Full heap collection 혹은 compaction에 소요되는 시간이 너무 긴 경우 발생할 수 있습니다.
이 경우, -Xgcpolicy:optavgpause 옵션을 적용하면, concurrent 하게 heap collection이 발생하게 되고, GC에 따른 pause시간이 감소하여, 전체적인 Response Time 향상을 기대할 수 있습니다.
적용 옵션 |
-Xgcpolicy:optavgpause |
Throughput이 너무 적게 나옵니다.
상황
CPU 및 Memory등의 capacity가 좋은 장비임에도 불구하고, WAS 서비스의 전체적인
Throughput이 너무 나오지 않습니다.
조치
이 경우, -Xgcpolicy:optthruput 옵션을 적용하면, concurrent 한 mark&sweep 작업을 막음으로써, 대부분의 Thread가Business Service를 수행하는데 사용되도록 유도하여 전체적인 Throughput을 향상시키는데 도움이 될 수 있습니다.
만일, CPU가 16장 이상인 고 사양 환경의 경우 –Xgcpolicy:subpool 옵션이 좀더 효과적인 성능을 발휘 할 수 있습니다.
적용 옵션 |
일반적인 경우 : -Xgcpolicy:optthruput |
16장 이상의 CPU 환경 : -Xgcpolicy:subpool |
Garbage Collection이 너무 자주 발생합니다.
상황
GC Interval이 매우 좁게 나타나며, GC count가 너무 높게 나옵니다.
조치
Application 특성에 비해 Heap Size가 너무 작게 설정되어 있을 수 있습니다.
또한, 이 경우 –Xgcpolicy:optthruput 옵션이 도움이 될 수 있습니다.
적용 옵션 |
-Xmx를 늘림 -Xgcpolicy:optthruput |
설정된 Heap Size와 실제 사용량의 차이가 너무 심하게 납니다.
상황
실제 WAS JVM에 할당한 Heap Size와 사용되는 Heap Size의 등락폭이 너무 심하게 자주 바뀝니다.
조치
Heap Size가 너무 크게 설정되어 있을 수 있습니다.
Heap Size를 줄이고, Generation Heap Space가 설정된 경우 ‘Nursery’영역의 Size를 좀더
할당해 주는 것도 도움이 될 수 있습니다.
적용 옵션 |
-Xmx를 줄임 -Xgcpolicy:optthruput |
CPU 16장 이상의 환경에서 WAS를 운영하는 경우, 권장 GC 정책은 무엇인가요?
상황
CPU 16장 이상의 AIX장비의 IBM JDK 1.5 이상 환경에서 WAS를 운영하고자 합니다.
권장 GC 정책은 무엇 인가요.
조치
이 경우 -Xgcpolicy:subpool 옵션을 권장합니다.
하지만 Business Application의 성격에 따라 다른 결과가 나올 수 있음으로, 다른 GC 정책과의 비교 Test가 필요합니다.
Heap Size를 넉넉하게 설정하였음에도 불구하고, Allocation Failure가 자주 발생합니다.
상황
Heap Size를 넉넉하게 설정하였습니다. Application에서 사용하는 Object들도 매우 큰 경우는 별로 발견되지 않는데, 잦은AF(Allocation Failure)가 발생하고 있습니다.
조치
메모리 단편화(Memory Fragmentation)를 의심해 볼 수 있습니다.
WAS의 JVM에 -Dibm.dg.trc.print=st_verify 를 설정하여, kCluster/pCluster 설정이 필요합니다. 또한, -Xloratio옵션을주어 LOA 영역에 대한 사이즈 조절도 때때로 유효한 경우가 있습니다.
적용 옵션 |
-Xk –Xp 설정 (-Dibm.dg.trc.print=st_verify 설정 후, 로그 분석을 통한 Size 설정)
stdout 로그에 verbosegc정보에 pinned=xxx 라는 형식으로정 보가 남게된다. |
-Xloratio 설정 |









{kind=link}
{kind=link}